
티스토리 뷰
Google Move Mirror: TensorFlow.js를 이용한 웹 기반 실시간 Pose Matching 구현
dancefirst 2022. 6. 21. 17:32유저 웹캠으로 입력받는 사용자 신체 동작과 가장 유사한 포즈 이미지를 실시간 매칭하여 보여주는 Move Mirror에 대한 소개 및 설명글. 2018년에 구글 Creative Lab이 수행한 실험성 프로젝트였으나, TensorFlow.js를 이용하여 실시간성을 담보하는 포즈 매칭에 대한 중요한 내용들을 담고 있기에 번역하여 소개한다.
Move Mirror를 크게 세 부분으로 나누어 설명.
- 인체 동작을 포함하는 Pose image dataset
- 포즈 이미지 데이터셋에 대한 Searching algorithm
- Pose matching 알고리즘
Move Mirror: An AI Experiment with Pose Estimation in the Browser using TensorFlow.js
By Jane Friedhoff and Irene Alvarado, Creative Technologists, Google Creative Lab
medium.com
이미지 데이터로부터 인체와 동작을 탐지하는 Pose estimation은 머신러닝과 컴퓨터 비전에서 가장 신나고 또 어려운 주제 중 하나다. 최근, 구글은 이미지 데이터로부터 포즈 데이터를 높은 정확도로 추정하는 SOTA 포즈 추정 모델 PoseNet을 공개했다. 이 모델은 흐릿하거나, 해상도가 낮거나, 흑백 컬러에도 대응 가능하다. 이 글은 처음부터 웹 환경을 염두에 둔 포즈 추정 라이브러리를 만드는 시발점이 된 실험 프로젝트의 내용을 소개한다.
몇달 전, 우리는 브라우저 상에서 아무렇게나 움직이는 동작과 가장 유사한 이미지를 찾아주는 Move Mirror의 프로토타입을 개발했다. 이 실험은 사용자의 움직임을 입력으로 받아, 스포츠, 춤, 무술, 연기 등등 모든 종류의 인체 동작을 담은 이미지들 중 가장 유사한 것을 찾아주는 독특한 경험을 제공한다. 우리는 이러한 경험을 웹 상에 구현하여 다른 사람들이 재미를 느끼고 머신러닝에 대해 배우기를 원했다. 하지만 우리는 한 문제에 부딪혔는데, 웹 환경에 특화되어 있으면서 publicly accessible한 동작 추정 모델이 존재하지 않았다는 것이다.
전형적으로, 포즈 데이터를 이용해 작업한다는 것은 특수한 하드웨어 또는 C++/Python 기반 컴퓨터 비전 라이브러리를 다뤄 본 경험을 요구한다. 우리는 따라서 구글이 개발한 인하우스 모델을 TensorFlow.js로 포팅하여 포즈 추정 작업에 대한 접근성을 더 높일 수 있겠다는 생각을 했다. TensorFlow.js는 브라우저 상에서 머신러닝 프로젝트가 동작하게끔 도와주는 자바스크립트 라이브러리다. 우리는 팀을 꾸려 수 개월에 걸쳐 라이브러리를 개발했고, 마침내 PoseNet을 내놓게 되었다. PoseNet은 웹 개발자 누구든지 특수한 카메라 장비나 C++/Python 기술이 없어도 웹브라우저 안에서 인체동작 기반 상호작용 기능을 구현할 수 있도록 돕는 오픈소스 툴이다.
PoseNet 공개와 더불어, 우리는 또 Move Mirror를 릴리즈 할 수 있었다. Move Mirror는 실험적인 놀이가 진지한 엔지니어링 작업에 어떤 기여를 할 수 있는지 보여줄 수 있는 일종의 증명이다. 우리는 연구팀, 제품개발팀 그리고 creative teams의 긴밀한 협업을 통해서 PoseNet과 Move Mirror를 구현하고 세상에 내놓을 수 있었다.

이제 우리가 이 실험을 어떻게 진행했는지, 웹브라우저 상에서 동작하는 포즈 추정에서 어떤 부분이 흥미로웠는지, 그리고 흥미롭게 느껴진 여러 아이디어에 대해 자세하게 소개해 보고자 한다.
What is pose estimation? What is posenet?
포즈 추정은 꽤 복잡한 문제다. 이미지에서 인체는 매우 다양한 형태와 크기로 주어진다. 트래킹해야 할 많은 joint가 존재하며(그리고 공간 상에서 인체 joint를 표현하는 방법도 매우 다양하다), 인체 주변에 다른 인체 또는 사물이 존재하여 가려짐이나 생략(occlusion) 문제가 발생하기 때문이다. 어떤 사람들은 휠체어 같은 신체 보조 기구를 사용하는데, 이 때문에 신체 일부가 카메라에 담기지 않게 된다. 어떤 사람들은 팔다리 일부가 가려지기도 하고 신체 비율도 매우 다양하게 나타난다. 우리는 이러한 다양한 신체들을 머신러닝 모델이 잘 이해하고 똑똑하게 추론할 수 있기를 원했다.

과거 기술자들은 포즈 추정 문제를 해결하기 위해 2d 이미지로부터 포즈를 추정하는 컴퓨터 비전 기법(like OpenPose) 뿐 아니라 특수 카메라 및 센서 장비들을 사용해 왔다. 하지만 이러한 솔루션은 효과적이긴 했지만 비싸거나 접근성이 낮은 기술을 요구했으며, C++이나 파이썬 언어나 컴퓨터 비전 라이브러리에 대한 경험을 요구하기도 했다. 때문에 일반적인 개발자들이 동작 추정과 관련된 실험을 빠르게 수행하기 어려웠다.
PoseNet은 단순한 web API로 이용 가능했으므로 우리는 자바스크립트를 활용해서 포즈 추정 실험을 빠르고 쉽게 프로토타이핑 할 수 있었다. 덕분에 우리는 HTTP POST 요청을 이미지의 base64 데이터와 함께 내부 엔드포인트로 보내는 일만 해주면 됐다. 이렇게 하면 API 엔드포인트는 다시 우리에게 거의 지연 없이 포즈 데이터를 보내주기 때문이다. 따라서 소규모 실험용 포즈 프로젝트의 진입장벽이 매우 낮아졌다. 자바스크립트 몇 줄에 API 키를 입력하기만 하면 웹 통신이 가능해지기 때문이다. 하지만 물론, 중앙화된 서버에 자기 자신의 사진을 전송하는 것을 불편해 하는 사람들도 존재한다. 우리가 제공하는 서버 또는 제3자의 서버에 의존하지 않고도 자신의 실험용 포즈 프로젝트를 할 수 있게 하려면 어떻게 해야 할까?
우리는 이것이 TensorFlow.js를 PoseNet과 연결하는 작업을 수행할 완벽한 기회라고 생각했다. TensorFlow.js는 사용자들이 서버에 의존하지 않고 브라우저에서 머신러닝 모델을 바로 사용할 수 있게 도와줄 수 있기 때문이다. PoseNet을 TensorFlow.js로 포팅함으로써, 웹캠이 장착된 데스크탑이나 핸드폰만 있으면 누구나 웹 브라우저 안에서 머신러닝 기술을 테스트해볼 수 있게 된다. 로우레벨의 컴퓨터 비전 라이브러리나 복잡한 백엔드, API와 씨름하지 않고도 말이다. 우리는 TensorFlow.js팀 및 구글 리서칭 팀과 협업하여 PoseNet 모델을 TensorFlow.js에 포팅할 수 있었다. (자세한 내용은 이 포스팅에서 확인)
TensorFlow.js에 포팅된 PoseNet은 다음과 같은 장점을 갖게 되었다:
Ubiquity/Accessibility
대부분의 개발자들은 텍스트 에디터와 웹 브라우저에 접근할 수 있으며, PoseNet의 사용은 HTML 파일에 두 개의 스크립트 태그를 추가하는 것으로 완성이다. 별도의 서버는 물론 필요하지 않다. 데이터를 얻기 위해 적외선 카메라나 센서와 같은 특수 장비도 필요하지 않다. 사실, 우리는 PoseNet이 저해상도, 흑백 그리고 품질이 낮은 이미지에도 작동하는 것을 확인했다.
Shareability
모든 것이 브라우저 안에서 동작하기 때문에, TensorFlow.js PoseNet 실험은 브라우저 상에서 매우 쉽게 공유될 수 있다. 운영체제에 맞춘 빌드를 할 필요도 없이, 웹페이지를 업로드하면 끝이다.
Privacy
모든 포즈 추정이 브라우저 안에서 수행되기 때문에, 이미지 데이터가 로컬 컴퓨터를 벗어날 필요가 없다. 포즈 분석을 수행하기 위해서 제어할 수 없는 제3자의 서버에 당신의 사진을 업로드할 필요 없이, 당신은 본인의 장비를 이용해 포즈 추정을 수행할 수 있다. Move Mirror에서 입력되는 당신의 사진 속 (x,y) 2차원 joint 데이터는 PoseNet이 우리의 포즈 데이터를 이용하여 매칭하고 출력하며, 이는 우리의 백엔드에서 수행된다. 그럼에도 당신의 이미지 자체는 여전히 어디로도 전송되지 않고 당신의 컴퓨터에만 존재한다.
*Move Mirror 또한 중앙화된 백엔드 상에서 포즈 매칭이 수행되며 입력 데이터를 전송받지만, 입력 이미지 자체가 전송되는 것이 아니라 이미지의 2차원 포즈 데이터가 전송되므로 프라이버시가 지켜질 수 있다는 의미
기술 이야기는 여기까지 하고, 디자인 얘기를 해 보자.
Design and Inspiration
우리는 첫 몇 주를 다양한 포즈 추정 프로토타입을 만지작거리며 보냈다. C++ 또는 키넥트 분야 배경을 가진 팀원들은 우리의 브라우저 상에서 우리의 웹캠만 사용하여 포즈 매칭된 스켈레톤을 볼 수 있다는 것을 보고 꽤 흥미로워 했다. 우리는 퍼펫 같은 다양한 것들을 시험한 끝에 Move Mirror로 발전하게 된 컨셉에 도달했다.
구글 Creative Lab에 소속된 팀원들 대다수가 조사와 탐구에 큰 흥미를 갖고 있다는 건 놀랄 일은 아니다. 포즈 추정으로 무엇을 할 수 있을까 이야기하는 과정에서, 우리는 포즈 데이터를 이용해서 아카이브를 탐색(search)한다는 아이디어에 이끌렸다. 만약 당신이 어떤 포즈를 취했는데, 그 동작과 유사한 결과를 찾을 수 있다면? 또는, 당신이 어떤 포즈를 취했는데 동일한 포즈이지만 전혀 다른 맥락의 이미지를 찾을 수 있다면? 무술, 요리, 스키 타기부터 첫 발을 내딛는 아기까지 온갖 인체 동작을 아우르는 이상하지만 매력적인 연결점들을 어떻게 찾아낼 수 있을까? 그게 얼마나 우리를 놀라게 하고, 즐겁게 하고, 웃게 할 수 있을까?


우리는 제스쳐 데이터를 사용해서 구글 어스의 유사한 라인을 탐색하는 Land Lines, 그리고 아카이브의 아이템을 포즈 매칭으로 찾아주는 온사이트 설치형 작업인 Cooper Hewitt의 Gesture Match 프로젝트로부터 영감을 받았다. 그러나 우리는 훨씬 빠르고 실시간성을 충족하는 방향을 추구했다. 우리는 블러링 처리한 사람들이 연속적으로 등장하는 이미지 스트림이 당신의 동작에 따라 끊임없이 출력되는 아이디어가 매우 마음에 들었다. The Johnny Cash Project에서 사용된 rotoscoping과 타임랩스 포토그래피 및 유튜브의 selife 타임랩스에 영감을 받아, 우리는 결코 쉽지 않은 '웹브라우저에서 동작하는 실시간 반응형 포즈 매칭'에 도전하기로 결정했다.

Building Move Mirror
PoseNet이 포즈 추정 영역을 크게 해결해주긴 했지만, 여전히 해결해야 할 수많은 문제들이 남아 있었다. 핵심적인 경험은 결국 입력되는 사용자 포즈에 매칭되는 이미지를 찾아내는 것에 달려 있었다. 당신이 서서 오른손을 든다면, Move Mirror는 마찬가지로 서서 오른손을 든 사람의 이미지를 찾아 주어야만 했다. 이것을 위해서 우리는 세 개의 컴포넌트가 필요했다: 이미지 데이터셋, 검색 테크닉 그리고 포즈 매칭 알고리즘이다. 지금부터 각 컴포넌트를 하나하나 살펴보자.
Building a dataset: searching for a diversity
쓸만한 데이터셋을 구축하기 위해, 우리는 광범위한 다양성을 가진 인체동작 이미지를 찾아야만 했다. 오른손을 들고 서 있는 포즈 이미지 400장이 있어도 다른 포즈들이 데이터셋에 포함되어 있지 않다면 의미가 없기 때문이다. 보다 일관된 경험을 제공하기 위해, 찾는 이미지의 범위를 전신을 포함하는 이미지만으로 제한했다. 결국, 우리는 움직임의 다양성 뿐 아니라 신체 유형, 피부색, 문화와 기타 물리적인 속성 측면에서도 다양성을 갖춘 비디오 데이터 셋을 구매했다. 우리는 이 비디오 셋을 8만 장의 스틸 프레임으로 쪼개어, PoseNet을 이용해 포즈 데이터를 추출한 뒤 저장했다. 이제 어렵고 또 중요한 부분, 포즈 매칭과 검색에 대해 살펴보자.

Pose matching: the challenge of defining similarity
Move Mirror 구현을 위해, 우리는 우선 'match'가 무엇인지 정의해야 했다. match는 유저의 움직임에 따라 입력된 포즈 데이터에 대해 리턴해 주는 이미지를 말한다. PoseNet에서 출력된 'pose data'는 "keypoints"라고 불리는 17개의 신체 또는 안면 부위의 2차원 좌표 데이터 집합을 의미한다. PoseNet은 입력 이미지에 포함된 17개 keypoint 각각에 대한 x, y 위치값을 반환하며, 추가적으로 해당 위치값에 대한 신뢰점수(confidence score)도 반환한다.
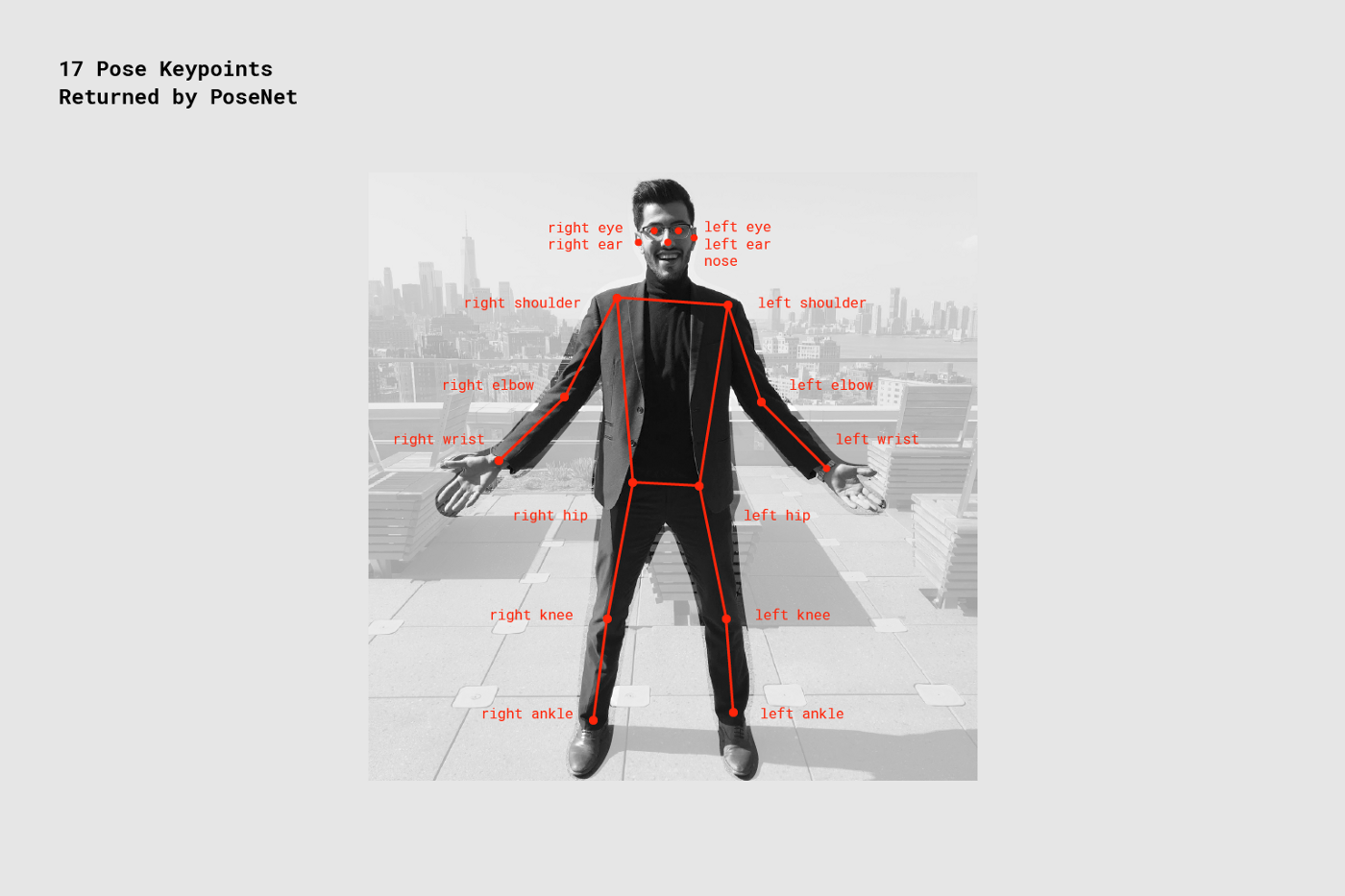
Matching strategy #1: cosine distance
17개 keypoint 집합을 벡터로 변환하여 고차원 공간에 시각화 했을 때, 가장 유사한 두 개의 포즈를 찾아내는 태스크는 고차원 공간 상에서 가장 가까운 거리에 있는 두 개의 벡터를 찾는 것으로 정의할 수 있다. 이 태스크는 cosine distance가 해주는 일과 완전히 같다.
Cosine similarity는 두 벡터 간의 유사도를 측정하는 지표다. 기본적으로 이것은 두 벡터 간의 각도를 계선하여 정반대면 -1, 정확히 같다면 1을 반환한다. 중요한 점은 cosine similarity는 magnitude(벡터의 크기)가 아닌 orientation을 측정한다는 점이다.

우리가 벡터와 각도를 얘기하고 있긴 하지만, 꼭 그래프 상의 선분에 국한되는 것은 아니다. 예를 들어, 우리는 cosine similarity를 두 개의 길이가 같은 텍스트 간의 수치적인 유사도를 계산할 때도 사용할 수 있다. Word2Vec을 써본 적이 있다면 당신은 간접적으로 cosine similarity를 사용해본 것이다. 실제로, cosine similarity는 두 개의 고차원 벡터 간의 관계를 하나의 수치값으로 축소시키는 데 유용한 방법이다.

입력 데이터는 JSON 형식이었지만, 우리는 JSON 형식의 값들을 1차원 어레이로 쉽게 변환할 수 있었다. 데이터 구조를 일관성 있고 예측가능하게만 한다면, 결과물로 나오는 어레이들은 동일한 방식으로 비교 가능하다. 그래서 우리의 첫 단계는, JSON 포맷의 데이터를 어레이로 변환하는 것이었다.

데이터를 어레이로 변환함으로써, 우리들은 34개 float으로 구성된 입력 어레이와, 마찬가지로 34개 float으로 구성된 데이터베이스의 어레이 간의 유사도를 코사인 유사도를 이용하여 측정할 수 있게 되었다. 우리들은 두 개의 길다란 어레이들을 가지고, 훨씬 파싱하기에 수월한 -1과 +1 사이의 유사도 점수를 얻는다.
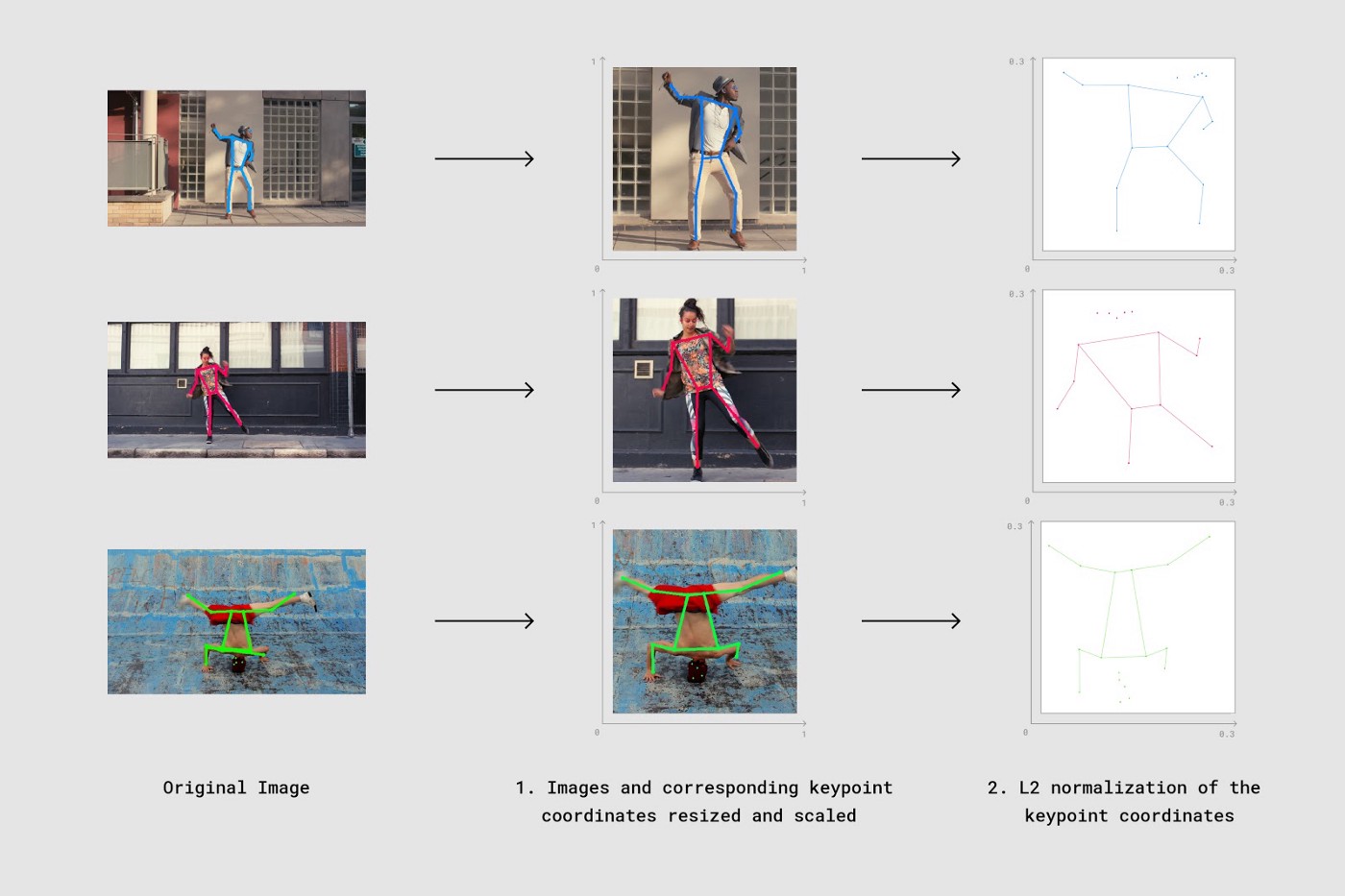
우리 데이터베이스에 있는 모든 이미지들은 저마다 다른 높이와 너비를 갖고 있으며, 이미지 내에서 인체가 등장하는 위치도 제각각이기 때문에(왼쪽, 우측 하단, 중앙 등) 일관성 있게 두 개의 데이터를 비교하기 위해서 2개의 추가적인 과정을 수행했다.
1. Resize and scale
우리들은 인체 바운딩 박스의 좌표값을 사용하여, 이미지와 각 키포인트 좌표값들을 동일한 사이즈로 crop & scale을 수행했다.
2. Normalize
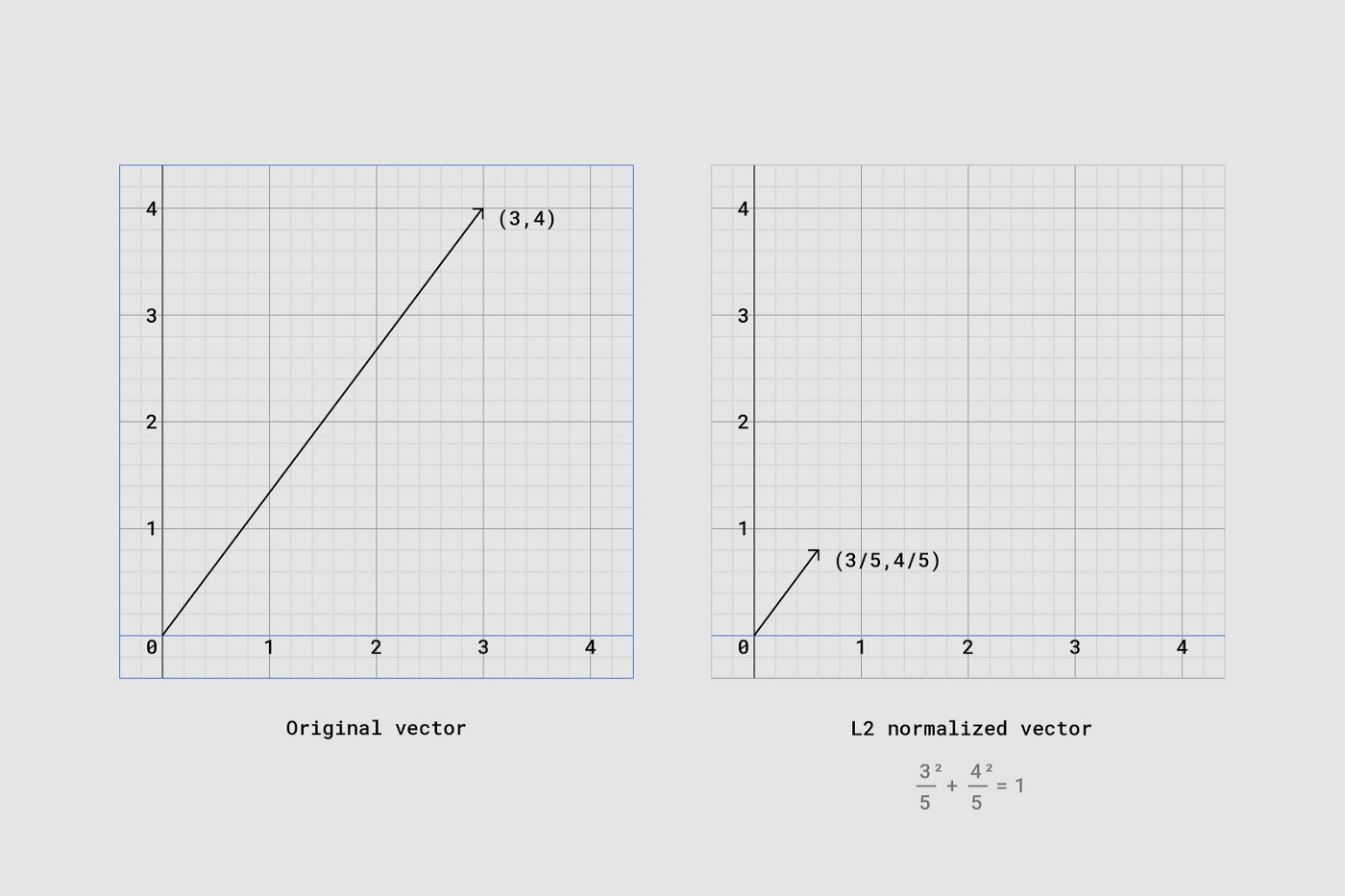
우리들은 결과 어레이의 키포인트 좌표값들에 대해 L2 normalization을 수행했다.
특히 2번째 단계에서 L2 normalization을 적용했는데, 이는 우리들이 입력 벡터가 단위 norm을 갖도록 스케일링을 했다는 의미다. 예를 들어, 당신이 L2 normalization을 수행한 벡터의 각 요소들을 제곱하여 합하면 그 값은 1이 된다. normalization이 벡터를 어떻게 변환하는지 아래 그래프를 보면 시각적으로 이해할 수 있다.
위에서 말한 2단계 과정을 시각화하면 아래와 같다.
벡터 어레이 형태로 저장된 키포인트 좌표값들을 normalize 함으로써, 우리들은 최종적으로 코사인 유사도를 바탕으로 한 유클리드 거리 기반의 코사인 거리를 계산하고 도출할 수 있다. 코사인 거리의 계산식은 아래와 같다.
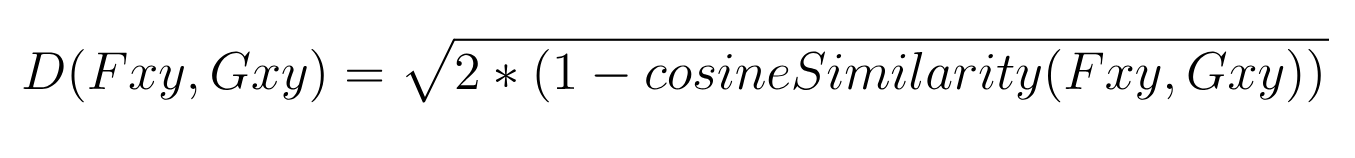
위 계산식에서 Fxy와 Gxy는 L2 normalization을 거쳐서 서로 비교하게 될 두 개의 포즈 벡터를 의미한다. 또한, Fxy와 Gxy는 17개 키포인트 각각에 대한 x, y 좌표값만을 가지고 있으며, 각 키포인트에 대한 신뢰도 점수는 포함하지 않는다.
이를 구현한 자바스크립트 코드는 대략 아래와 같다.
// https://gist.github.com/irealva/6d6b7cacda0bba2f41117142105cc6dd#file-movemirrorcosinedistance-js
// Great npm package for computing cosine similarity
const similarity = require('compute-cosine-similarity');
// Cosine similarity as a distance function. The lower the number, the closer // the match
// poseVector1 and poseVector2 are a L2 normalized 34-float vectors (17 keypoints each
// with an x and y. 17 * 2 = 34)
function cosineDistanceMatching(poseVector1, poseVector2) {
let cosineSimilarity = similarity(poseVector1, poseVector2);
let distance = 2 * (1 - cosineSimilarity);
return Math.sqrt(distance);
}
깔끔하지 않은가? 하지만 아직 끝이 아니다.
Matching strategy #2: weighted matching
코사인 거리를 이용하는 접근법에는 큰 허점이 있다. 앞서 예시로 든 두 개의 문장들 "Jane likes to code"와 "Irene likes to code"는 static하다. 따라서 두 문장을 비교한 결과는 100%의 신뢰도를 갖는다. 그러나 포즈 추정은 그렇게 딱 떨어지는 문제가 아니다. 실제로, 우리가 각 조인트의 위치를 추정하려고 할 때, 100%의 신뢰도를 얻는 것은 거의 불가능하다. 100%에 매우 근접한 수치를 얻을 수는 있겠지만, 우리가 X-ray 기계가 아닌 이상, 100% 신뢰도를 달성할 가능성은 매우 희박하다. 때로 우리는 조인트를 아예 찾지 못할 수도 있고, 우리가 인체에 대해 알고 있는 지식에 기반해 가장 그럴듯한 추측을 해야만 할 수도 있다.

17개 조인트에 대한 데이터 각각에 대해서는 따라서 신뢰도 점수가 부여된다. 어떤 조인트는 매우 명확히 이미지에 나타나 높은 신뢰도 점수를 얻지만, 일부만 나타나거나 가려진 신체 조인트는 낮은 신뢰도 점수를 갖게 된다. 이러한 신뢰도 점수 정보를 무시한다면, 매우 중요한 정보를 무시하게 되는 것이며, 따라서 실제로는 신뢰할 수 없는 데이터에 대해 지나치게 높은 가중치와 중요도를 부여하게 될 수 있다. 이는 궁극적으로 최종적인 포즈 매칭 결과에 악영향을 미치는 노이즈로 작용할 것이다.
코사인 거리가 대체로 유용하고 효과적이지만, 우리는 PoseNet이 예측한 위치에 실제로 조인트가 존재할 확률값인 신뢰도 점수를 유사도 점수 계산식에 통합하면 문제를 개선할 수 있을 것이라고 생각했다. 기본적으로, 우리는 높은 신뢰도 점수를 갖는 조인트 데이터가 유사도 지표에 더 많은 영향을 미치고, 낮은 신뢰도 점수를 갖는 조인트 데이터는 적은 영향을 미치기를 원했다. 구글 연구팀 George Papandreou와 Tyler Zhu는 위와 같은 로직을 정확하게 수행하는 새 계산식을 만들어 주었다:

위 계산식에서, F와 G는 L2 normalization을 거친 뒤 비교하게 될 두 개의 포즈 벡터를 의미한다. Fck는 F에 속한 17개 키포인트 중 k번째 키포인트에 대한 신뢰도 점수를 의미한다. Fxy와 Gxy는 각 포즈 벡터의 k번째 키포인트에 대한 x, y 좌표값을 의미한다. 전체 계산식을 완벽하게 이해하지 못해도 괜찮다. 중요한 것은 우리가 매칭 퍼포먼스를 개선하기 위해 신뢰도 점수를 추가로 이용했다는 점을 이해하는 것이다. 다음 자바스크립트 코드를 보면 좀 더 구체적으로 이해할 수 있을 것이다.
// https://gist.github.com/irealva/735b2fb2810140e9fd4e645912262815#file-movemirrorweighteddistance-js
// poseVector1 and poseVector2 are 52-float vectors composed of:
// Values 0-33: are x,y coordinates for 17 body parts in alphabetical order
// Values 34-51: are confidence values for each of the 17 body parts in alphabetical order
// Value 51: A sum of all the confidence values
// Again the lower the number, the closer the distance
function weightedDistanceMatching(poseVector1, poseVector2) {
let vector1PoseXY = poseVector1.slice(0, 34);
let vector1Confidences = poseVector1.slice(34, 51);
let vector1ConfidenceSum = poseVector1.slice(51, 52);
let vector2PoseXY = poseVector2.slice(0, 34);
// First summation
let summation1 = 1 / vector1ConfidenceSum;
// Second summation
let summation2 = 0;
for (let i = 0; i < vector1PoseXY.length; i++) {
let tempConf = Math.floor(i / 2);
let tempSum = vector1Confidences[tempConf] * Math.abs(vector1PoseXY[i] - vector2PoseXY[i]);
summation2 = summation2 + tempSum;
}
return summation1 * summation2;
}
신뢰도 점수까지 사용하는 접근을 통해 우리는 더 정확한 결과를 얻을 수 있었다. 인체 일부가 가려지거나 생략되더라도, 개선된 유사도 계산 알고리즘은 사용자가 입력하는 인체동작 포즈와 비슷한 이미지를 더 잘 찾아냈다.

Searching pose data at scale: 80,000 images in ~15ms
마지막으로, 우리들은 검색할 데이터베이스 스케일이 커진 상황에서 포즈 검색 및 매칭을 수행할 방법을 찾아야 했다. 물론 가장 쉬운 방법은 데이터베이스 전체를 모두 조회(brute-force)하는 것이다. 데이터베이스에 포즈 이미지가 10개만 있다면 이 방법을 써도 괜찮다. 그렇지만, 당연히 이미지 10개로는 충분하지 않다. 거의 모든 인체 동작을 커버하려면 우리들은 못해도 수만 장의 이미지들이 필요하다. 8만개 이미지로 구성된 데이터베이스 전체를 실시간에 가까운 속도로 매번 통째로 조회하는 것은 매우 어려운 일이다. 그래서, 우리의 다음 문제는 커다란 데이터베이스에서 어떤 부분을 조회하지 않고 어떤 부분이 우리가 원하는 부분인지 빠르게 탐색해내는 방법을 찾아야 했다. 우리가 더 많은 데이터베이스를 조회하지 않고 스킵할 수록, 매칭 결과의 반환도 그만큼 빨리 이루어질 것이다.
우리는 Zach Lieberman과 Land Lines experiment에서 단서를 얻어, "vantage-point tree"(JS library link)라고 불리는 자료구조를 우리의 포즈 데이터에 적용했다. vantage-point tree는 데이터를 2개의 카테고리로 재귀 반복하여 쪼갠다. threshold를 기준으로 특정 vantage-point에 가까운 카테고리와 먼 카테고리로 나누는 것이다. 이러한 재귀적인 정렬 프로세스는 필요에 따라 생략하거나 건너뛸 수 있는 트리형 자료구조를 생성한다. 이 기법은 K-D tree와 유사하기도 한데, vantage point trees에 대해 더 자세한 설명은 이 링크를 참조할 것.
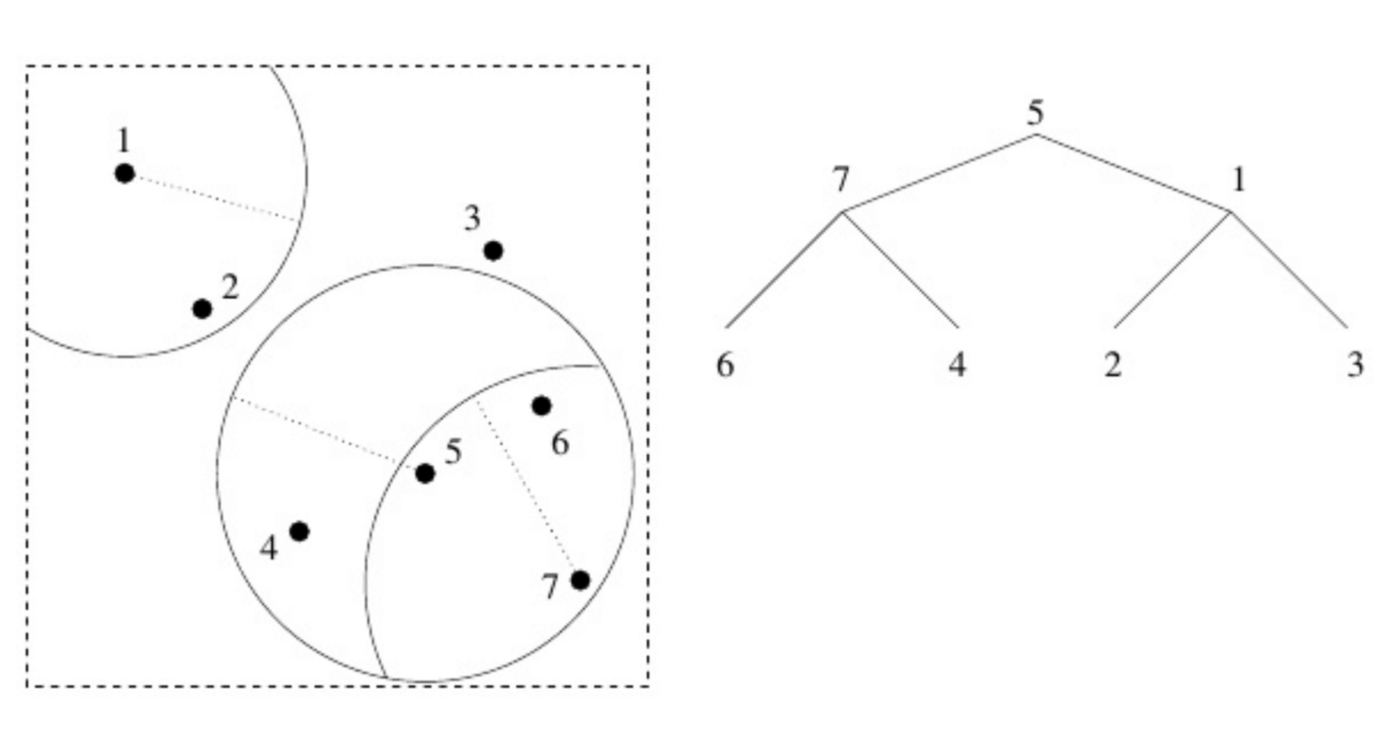
vp tree에 대해 좀더 자세히 살펴보자. 완벽하게 이해하지 못해도 괜찮다. 기본 원리를 이해하는 것이 중요하다. 데이터 공간에는 특정 포인트 집합이 존재하고, 우리는 랜덤하게 포인트 하나를 뽑아서 root으로 삼는다. 위 이미지에서는 5번 포인트가 우리의 root다. root 포인트를 중심으로 하는 원을 그리면, 어떤 데이터는 원 안에 들어오고 어떤 데이터는 원 바깥에 위치하게 된다. 그러면 우리는 원 내부에서 하나(1번 포인트), 원 바깥에서 하나(7번 포인트)를 고른다. 그 다음, 2개 포인트 각각에 대해 동일한 방식을 반복한다. 포인트를 중심으로 하는 원을 그리고, 원 안팎에서 다시 포인트 2개를 뽑고 자식 vantage point로 갖는다. 핵심은, 만약 당신이 5번 포인트에서 시작했다면 1번 포인트보다 7번 포인트가 더 가깝다는 것을 알 수 있고, 그렇다면 1번 포인트를 포함하여 그 자식 포인트들까지 조회하지 않고 넘어갈 수 있다는 것이다.
이러한 트리 구조를 사용함으로써, 우리는 더 이상 데이터베이스를 통째로 조회하며 유사도를 계산할 필요가 없어졌다. 입력 포즈 데이터가 트리 내의 특정 노드와 충분히 유사하지 않다면, 그 노드의 자식 노드들 또한 충분히 유사하지 않을 것이라고 가정할 수 있다. 데이터베이스 entry 전체를 검색할 필요 없이, 위 방식으로 트리를 건너뛰어 가면서 비슷한 포즈를 탐색할 수 있다. 안전하고 신뢰할 수 있는 방식으로 우리에게 필요하지 않은 커다란 부분들을 빠르게 확인하고 버릴 수 있게 된다.
vantage point tree는 결과적으로 검색 속도를 크게 끌어올려 목표했던 실시간 경험을 제공할 수 있게 되었다. 조금 까다로운 방법이었지만 vp tree를 도입한 효과는 우리의 기대를 충족시켰다.
위 기법을 직접 시도해 보고 싶은 사람들은 자바스크립트 라이브러리 vptree.js를 이용해 vp tree를 구현한 아래 코드를 참고하면 된다. 앞서 설명한 특정 거리 기반 매칭 기능을 이용하는 방식이지만, 당신이 원하는 다른 거리 함수로도 vp tree를 빌드하여 적용해 볼 것을 추천한다.
// https://gist.github.com/irealva/96a6b04ef4fe8ffbb081575e6e17fa35#file-movemirrorvptree-js
const similarity = require('compute-cosine-similarity');
const VPTreeFactory = require('vptree');
const poseData = [ […], […], […], …] // an array with all the images’ pose data
let vptree ; // where we’ll store a reference to our vptree
// Function from the previous section covering cosine distance
function cosineDistanceMatching(poseVector1, poseVector2) {
let cosineSimilarity = similarity(poseVector1, poseVector2);
let distance = 2 * (1 - cosineSimilarity);
return Math.sqrt(distance);
}
function buildVPTree() {
// Initialize our vptree with our images’ pose data and a distance function
vptree = VPTreeFactory.build(poseData, cosineDistanceMatching);
}
findMostSimilarMatch(userPose) {
// search the vp tree for the image pose that is nearest (in cosine distance) to userPose
let nearestImage = vptree.search(userPose);
console.log(nearestImage[0].d) // cosine distance value of the nearest match
// return index (in relation to poseData) of nearest match.
return nearestImage[0].i;
}
// Build the tree once
buildVPTree();
// Then for each input user pose
let currentUserPose = [...] // an L2 normalized vector representing a user pose. 34-float array (17 keypoints x 2).
let closestMatchIndex = findMostSimilarMatch(currentUserPose);
let closestMatch = poseData[closestMatchIndex];
Move Mirror 프로젝트에서 우리는 사용자가 입력한 포즈와 가장 유사한 이미지 1장만을 리턴한다. 그러나 디버깅을 위해, vp tree를 동일하게 사용하여 가장 유사한 top 10개 또는 20개 이미지를 리턴할 수도 있었다. 이 방식으로 우리는 데이터를 확인하는 디버깅 툴을 만들었고, 데이터셋에서 누락되거나 빠진 부분들이 무엇인지 확인하는 데 큰 도움이 되었다.

In The Future
우리는 수영선수, 요리사, 댄서, 아기 등 다양한 사람 이미지들이 나의 움직임을 따라하는 듯한 즐거운 경험을 할 수 있었다. 그리고 이 기술은 훨씬 더 재미있는 영역으로 발전할 수 있을 것이다. 댄스 영상, 고전영화 클립, 뮤직비디오 같은 영상 아카이브에서 자신의 동작과 유사한 이미지를 집 거실에서 프라이버시를 지키며 검색해볼 수 있다고 상상해 보라. 아니면, 이 기술을 활용해서 동작 점수를 기반으로 홈 요가를 배워볼 수도 있을 것이다. Move Mirror는 앞으로 만들어질, 누구나 쉽게 접근할 수 있는 수많은 in-browser 포즈 추정 프로젝트들 중의 단 하나에 불과하다.
Move Mirror 웹사이트에 접속해서 포즈를 취해 보라. TensorFlow.js로 포팅된 PoseNet에 관심이 있다면 repo와 blog post를 확인해 봐도 좋을 것이다. 당신은 또 Experiments with Google 페이지에서 더 많은 실험들을 찾아볼 수도 있다. 이 기술로 당신이 멋진 프로젝트를 만들기를 기대하며, 만들었다면 #tensorflowjs와 #posenet 태그로 공유하는 것도 잊지 말길 바란다.
References / Further Readings
https://experiments.withgoogle.com/collection/ai/move-mirror/view
AI Experiments: Move Mirror
What is this? Move Mirror is a machine learning experiment that lets you explore pictures in a fun new way, just by moving around. Move in front of your webcam and Move Mirror will match your real-time movements to hundreds of images of people doing simila
experiments.withgoogle.com
https://blog.solarmagic.dev/ml/2021/04/16/pose-similarity/
두 사람의 동작 유사도를 계산하기
이글은 2020년 8월 4일에 작성한 글 을 옮긴 글입니다.
blog.solarmagic.dev
'AI Motion Capture > Learnings' 카테고리의 다른 글
| SMPL 휴먼 모델 및 파라미터 이해하기 (0) | 2022.04.14 |
|---|
- Total
- Today
- Yesterday
- 컴퓨터그래픽스
- 컴퓨터그래픽스 강의
- tensorflow.js
- 컴퓨터그래픽스 좌표계와 변환
- 3d affine transform
- vertex shader
- 원유로필터
- 고려대학교 한정현
- PoseNet
- 메타버스
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |