
티스토리 뷰
Overview
ROMP를 비롯하여, 현재 공개되는 대부분의 Human Pose Estimation 인공지능 모델은 추정된 포즈 데이터 포맷으로 SMPL을 채택하고 있다. ROMP 출력 결과를 블렌더에 임포트하는 QuickMocap의 경우, 'poses' / 'betas' / 'cam' 데이터를 활용하는데, 이러한 데이터가 정확히 무엇을 의미하는지를 이해하는 것은 노이즈 필터 적용을 위한 초석이 된다.
Objectives
SMPL Human Model Introduction 포스트를 번역하여 아래 내용을 파악하고 이해한다.
* 3D 오브젝트를 표현하는 방식 및 데이터 구성요소
* SMPL 휴먼 오브젝트 합성 파이프라인 상세
Takeaways / Further Questions
[1] SMPL은 크게 3단계 과정으로 작동한다.
1. 형태 정보로부터 메쉬 구축
2. 구축된 메쉬로부터 관절 위치 추정
3. 추정된 관절 위치를 기반으로 실제 포즈에 맞게 메쉬 변환
-> 포즈 데이터는 24개 관절 위치값으로 구성되므로, 최초 형태 정보로부터 구축된 3D 메쉬 품질을 따라간다.
[2] 기본적으로 모델에 입력하는 영상의 퀄리티는 중요하다.
SMPL은 기본적으로 인식된 인간 신체의 형태 정보로부터 출발하며, 형태 정보로부터 24개 관절 위치가 결정되기 때문이다. Pose Estimation 모델이 비디오로부터 인체 형태정보를 정확하게 인식하지 못한다면 SMPL 메쉬가 정상적으로 구축되지 않고, 따라서 24개 관절의 위치도 불확실해진다. 기본적으로 생각해볼 수 있는 영상 퀄리티의 세부 조건들은 다음을 생각해볼 수 있다.
- 입력 영상에서 인체가 배경과 명확하게 구별될 것 (색상과 형태 측면에서)
- 입력 영상에 등장하는 인체가 human estimation 모델 학습에 사용된 데이터셋과 최대한 동일한 조건일 것
- 카메라-피사계 심도 (camera distance)
- 인체가 착장한 의복 (치마? 쫄바지? 치마바지? 헐렁한 힙합 바지?)
- 인체가 취하는 포즈 (데이터셋에 포함되지 않은 괴상하거나 과도하게 복잡한 동작들)
-> 상술내용을 기준으로 한 영상 퀄리티에 따라, 인공지능 모델의 인체 인식 및 모션퀄리티 추정 결과 품질에 영향이 발생하는지 실증 테스트 필요.
[3] SMPL 아웃풋의 포즈 데이터는 고정된 3차원 공간에서의 절대좌표값이 아니다.
24개 조인트에 대해 각각 3차원 실수값이 부여되지만 이는 axis-angle rotation representation으로 인코딩된 형태이며, 부모 관절에 대한 relative rotations를 의미한다. 24개 조인트의 hierarchy는 pelvis joint로부터 시작되고, pelvis joint의 location은 root / cam_trans에 대해 상대 정의되며, 이러한 pelvis에 대해 자식 관계인 나머지 23개 조인트가 상대적으로 정의된다.

- 인체에 대한 3D 재구축 과정에서 pelvis joint에 대한 추정이 불확실하면 그 영향은 나머지 23개 joint에 고스란히 전이될 수 있다.
- pelvis joint location을 기반으로 23개 joint의 상대위치가 결정되기 직전 단계에 개입하여, pelvis joint location 추정치를 인위적으로 조정(i.e. 아웃라이어 여부 판단 후 정상화 처리)할 수 있다면 전체적으로 조인트 위치 추정 퀄리티가 향상될 수 있다.
- 그러나 대부분의 human pose estimation 모델은 사전학습된 SMPL 모델을 그대로 사용하므로, joint locations 추정 과정에 개입하는 것은 현실적으로 어렵다.
- Human pose estimation 모델과 SMPL 모델 사이에서 이루어지는 데이터 교환 및 처리 프로세스를 검토하고 개선이 가능한 개입 포인트를 확인해볼 필요는 있다.
[4] 커스텀 3D 모델에 대한 모션 리타겟팅 퀄리티 관점에서, shape parameter는 중요하지 않다.
3D 애니메이션의 핵심이 되는 pose data의 추정에 shape parameter가 중요한 역할을 하는 것은 사실이지만, 일단 pose data가 도출 되었다면 그 이후 shape parameter는 필요하지 않다. 커스텀 3D 모델의 조인트에 포즈 데이터를 매핑하여 모션 리타겟팅을 수행하는 것이 핵심이며, SMPL 표준인체 메쉬 정보는 버려지기 때문이다.
* 최종적으로 모션 리타겟팅을 고려했을 때, pose 외에 shape parameter에 대한 스무딩은 필요한가, 필요하지 않은가? -> 리타겟팅 퀄리티 영향 여부를 실제 테스트로 검증할 필요
* 마찬가지로, cam_trans에 대한 스무딩은 리타겟팅 최종 퀄리티에 영향을 미칠까? 실증 테스트 필요할 듯
이하 참고 포스팅 번역내용 상세.
SMPL Human Model Introduction
본고는 SMPL 논문의 이론적인 내용과, 사전학습된 SMPL 모델로부터 휴먼 메쉬 인스턴스를 합성하는 넘파이 기반 구현코드 간의 이해를 돕기 위해 작성되었다. 개인적으로, 나는 SMPL 모델 구현과 관련해 더 자세하게 알고 싶어서 이 글을 작성했다.
- Introduction
- Human synthesis pipeline
- Shape Blend Shapes
- Pose Blend Shapes
- Skinning (Joint Locations Estimation / Skinning deformation)
- Conclusion
Introduction
3D 오브젝트는 일반적으로 3D 형태를 인코딩하기 위해 vertices와 triangles로 표현된다. 오브젝트가 디테일할 수록 더 많은 vertices가 필요해진다. 그러나, 인체 오브젝트의 경우 3D 메쉬의 representation은 신장, 뚱뚱한 정도, 가슴 둘레, 배가 나온 정도, 포즈 등을 축으로 갖는 더 낮은 차원의 공간으로 압축할수 있다. 이러한 압축된 representation은 더 작은 크기의 데이터로 더 의미있는 정보를 포함한다.
SMPL은 두 종류의 파라미터로 인체를 인코딩하는 통계 모델이다.
- Shape parameter: 10개의 실수값(PCA coefficients)으로 구성된 shape vector로, 각 실수값은 신장(tall/short) 축과 같은 특정 축 방향에서 인체 오브젝트의 팽창/수축 정도 등으로 해석될 수 있다.
- Pose parameter: 24x3 실수값으로 구성된 pose vector로, 각 joint 파라미터에 대응하는 relative rotation을 보존한다. 각 rotation은 axis-angle rotation representation에서 임의의 3차원 벡터로 인코딩된다.
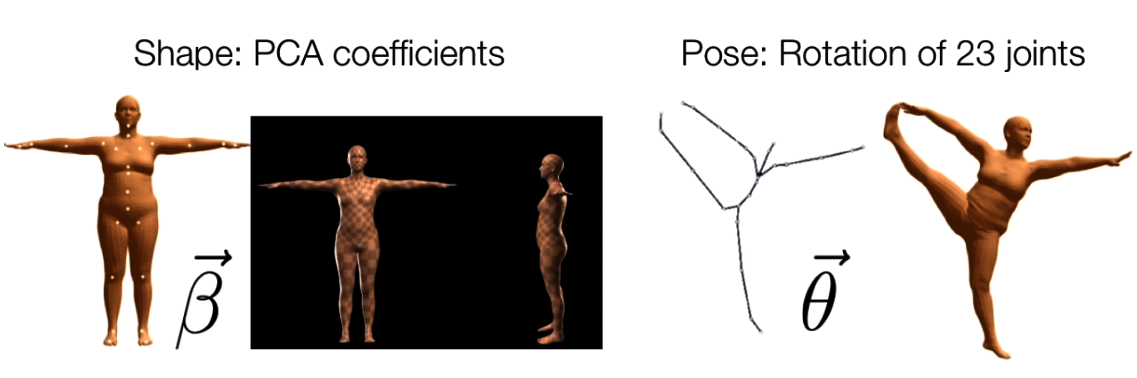
예를 들어, 아래 작성된 코드는 shape / pose 파라미터로 랜덤한 인체를 샘플링한다. 절편이동(shift) 및 곱하기 연산은 SMPL 모델의 표준 파라미터 범위에 맞게 랜덤 실수값을 조정하기 위해 적용되었다. 파라미터 범위 조정을 하지 않으면 합성된 메쉬는 외계인처럼 될 것이다.
pose = (np.random.rand((24, 3)) - 0.5) # shift
beta = (np.random.rand((10,)) - 0.5) * 2.5 # shift and multiplication
Human synthesis pipeline
새로운 휴먼 인스턴스를 SMPL 모델로부터 합성하는 프로세스는 아래와 같이 3단계로 구성된다.
Stage 1: Shape Blend Shapes
이 단계에서 템플릿(또는 mean) 메쉬

Stage2: Pose Blend Shapes
rest pose 상태로 identity mesh를 만든 다음, 특정한 포즈로 인해 발생한 deformation correction 정보를 포함하는 vertex displacements를 더해준다. 즉 다음 단계인 "Skinning"에서의 non-rest pose를 위해, 두번째 단계에서 rest pose에 대해 일정량의 deformation을 수행한다.
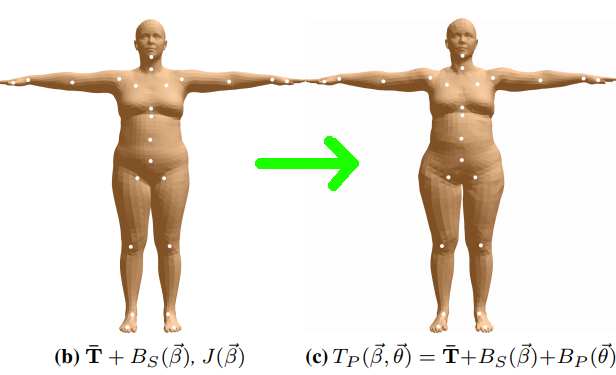
Stage3: Skinning
직전 단계에서 만들어진 각각의 mesh vertex는 joint deformation에 대한 가중 결합(weighted combination)으로 변환된다. 간단히 말해, joint가 vertex에 가까울수록 joint는 vertex를 더 강하게 회전/변환시킨다.

Shape Blend Shapes
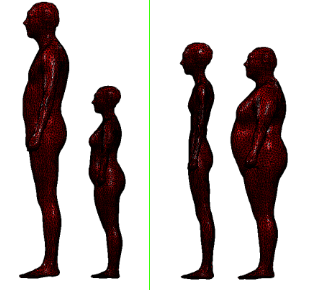
rest pose shape는 shape 주성분 또는 vertex deviation과 mean shape의 선형결합을 더해줘서 만든다. 이 값은 데이터셋에 포함된 모든 메쉬들의 주 변화량(principal changes)을 의미한다. 특히, 각 주성분은 (6890x36890x3) 매트릭스로서 평균 메쉬에 대응하는 vertices로부터의 vertex displacements
시각화된 이미지를 보면, 첫번째 주성분은 신장의 차이를 설명하고 두번째 주성분은 체중 변화를 설명하고 있는 것으로 보인다.
이하 코드는 SMPL 모델로부터 추출한 10개 주성분을 선형 결합하여 새로운 메쉬를 생성한다. 더 많은 갯수의 주성분을 사용할 수록 reconstruction 오차는 줄어들 것이다. 하지만 Maxplank Institute가 제작한 SMPL 모델은 10개의 주성분만을 제공하고 있다.
# shapedirs: 6890x3x10: 10 principal deviations
# beta: 10x1: the shape vector of a particular human subject
# template: 6890x3: the average mesh from the dataset
# v_shape: 6890x3: the shape in vertex format corresponding to the shape vector
v_shaped = self.shapedirs.dot(self.beta) + self.v_template
Pose Blend Shapes
SMPL 모델에서 인체 뼈대는 아래 이미지에서 하얀 점으로 찍혀 있는 24개 관절계(hierarchy of joints)로 표현된다. 24개 관절계는 부모-자식 관계로 각 관절이 서로 연결되어 있는 키네마틱 트리로 정의된다.

24개 관절계는

23개 관절부의 상대 로테이션 값
# self.pose : 24x3 the pose parameter of the human subject
# self.R : 24x3x3 the rotation matrices calculated from the pose parameter
pose_cube = self.pose.reshape((-1, 1, 3))
self.R = self.rodrigues(pose_cube)
# I_cube : 23x3x3 the rotation matrices of the rest pose
# lrotmin : 207x1 the relative rotation values between the current pose and the rest pose
I_cube = np.broadcast_to(
np.expand_dims(np.eye(3), axis=0),
(self.R.shape[0]-1, 3, 3)
)
lrotmin = (self.R[1:] - I_cube).ravel()
# v_posed : 6890x3 the blended deformation calculated from the
v_posed = v_shaped + self.posedirs.dot(lrotmin)
Skinning

이 단계에서 rest pose의 vertex는 global joint transformations (rotation + translation)의 가중결합으로 변환된다. 직전 단계에서 joint rotations는 이미 대상 인체의 포즈 파라미터로부터 계산한 상태이지만, joint translation 부분은 대응하는 대상 인체의 rest pose로부터 추정될 필요가 있기에 skinning 단계가 필요하다.
Skinning_Joint Locations Estimation
SMPL 모델의 경우 mesh가 연결되는 방식/구조, 즉 mesh topology가 고정되어 있으므로 각 joint location은 joint를 감싸고 있는 주변 vertices의 평균으로 추정할 수 있다. 이 평균값은 각 조인트에 대한 vertex weight 집합을 정의하는 데이터셋으로부터 학습된 joint regression matrix로 표현된다. 아래 이미지에서 볼 수 있듯, 무릎 조인트는 서로 다른 가중치를 갖는 붉은색 vertices의 선형결합으로 계산될 것이다.

이하 코드는 rest pose 메쉬로부터 joint location을 회귀 연산하는 작업을 수행한다.
# v_shape: 6890x3 the mesh in neutral T-pose calculated from a shape parameter of 10 scalar values.
# self.J_regressor: 24x6890 the regression matrix that maps 6890 vertex to 24 joint locations
# self.J: 24x3 24 joint (x,y,z) locations
self.J = self.J_regressor.dot(v_shaped)
Skinning_Skinning deformation
이상의 작업으로부터 수행되는 조인트 변환에 따라 이웃하는 vertices 변환이 이루어지는데, 각 vertex는 서로 다른 영향력을 지니고 있다. 어떤 vertex가 조인트로부터 멀리 위치할 수록, 조인트 변환에 따른 영향도 적게 받는다. 따라서, 최종적인 vertex는 24개 조인트에 의해 변환된 버전의 vertex의 가중평균으로 계산할 수 있다.
이하 코드는 우선적으로 부모 매트릭스와 로컬 매트릭스를 재귀적으로 결합함으로써 global transformation을 계산한다. 이렇게 계산된 global transformation에서 rest pose에 속한 조인트들에 대응하는 transformations을 제거한다. 각 vertex의 최종적인 transformation은 서로 다른 가중치로 24개 global transformations를 블렌딩함으로써 계산된다.
이하 코드는 상술한 단계를 수행한다.
# world transformation of each joint
G = np.empty((self.kintree_table.shape[1], 4, 4))
# the root transformation: rotation | the root joint location
G[0] = self.with_zeros(np.hstack((self.R[0], self.J[0, :].reshape([3, 1]))))
# recursively chain transformations
for i in range(1, self.kintree_table.shape[1]):
G[i] = G[self.parent[i]].dot(
self.with_zeros(
np.hstack(
[self.R[i],((self.J[i, :]-self.J[self.parent[i],:]).reshape([3,1]))]
)
)
)
# remove the transformation due to the rest pose
G = G - self.pack(
np.matmul(
G,
np.hstack([self.J, np.zeros([24, 1])]).reshape([24, 4, 1])
)
)
# G : (24, 4, 4) : the global joint transformations with rest transformations removed
# weights : (6890, 24) : the transformation weights for each joint
# T : (6890, 4, 4): the final transformation for each joint
T = np.tensordot(self.weights, G, axes=[[1], [0]])
# apply transformation to each vertex
rest_shape_h = np.hstack((v_posed, np.ones([v_posed.shape[0], 1])))
v = np.matmul(T, rest_shape_h.reshape([-1, 4, 1])).reshape([-1, 4])[:, :3]
# add with one global translation
verts = v + self.trans.reshape([1, 3])
Conclusion
본고에서 우리는 Maxplank Institute가 개발, 훈련한 SMPL 모델에서 새로운 인체 오브젝트를 합성하는 과정을 살펴보았다. 우리는 rest pose 형태를 재구축하기 위해 주성분을 결합한 뒤, 결합된 주성분으로부터 joint locations를 회귀 연산을 수행하는 방법을 배웠다. 또한 포즈 변화로부터 발생된 변형에 대한 correction을 예측하는 방식, 그리고 rest pose 메쉬에 global joint transformation을 적용하는 방법을 배웠다. 더 자세한 내용은 SMPL 논문을 참고 부탁드린다.
'AI Motion Capture > Learnings' 카테고리의 다른 글
| Google Move Mirror: TensorFlow.js를 이용한 웹 기반 실시간 Pose Matching 구현 (0) | 2022.06.21 |
|---|
- Total
- Today
- Yesterday
- 컴퓨터그래픽스 강의
- vertex shader
- 컴퓨터그래픽스
- tensorflow.js
- 고려대학교 한정현
- 메타버스
- 원유로필터
- PoseNet
- 컴퓨터그래픽스 좌표계와 변환
- 3d affine transform
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |